
スクレイピングにおいて、HTML要素の特定する手段は、XPathとCSSセレクターの2つがあります。Pythonでスクレイピングを始めた当初、どっちで要素を特定するか迷いました。迷わないように参考になる情報をまとめておきました。
XPathとCSSセレクターの比較
XPathかCSSセレクターかですが、ライブラリから見るとCSSセレクターの一択な感があります。しかし、表現の幅の広さでみるとXPathの方が圧倒的に有利です。
ライブラリのXPathとCSSセレクターのサポート状況
この通り使うライブラリによっては、選択の余地なしです。
| ライブラリ | XPath | CSSセレクター |
|---|---|---|
| lxml | 〇 | 〇 |
| Beautiful Soup | × | 〇 |
| selenium | 〇 | 〇 |
| pyquery | × | 〇 |
ちなみに、lxmlのCSSセレクターは、パッケージ内にlxml.cssselectモジュールという形で提供されています。
XPathとCSSセレクターの要素特定の書き方の比較
下にある通り、CSSセレクターの方が記述が簡単です。とても覚えやすいです。しかし、残念なことに、XPathにできるのに「表現不可」なものが存在します。
| ターゲット要素 | XPath | CSSセレクタ |
|---|---|---|
| 全要素 | //* | * |
| p要素 | //p | p |
| p要素の全要素 | //p/* | p>* |
| ID属性がfooの要素 | //*[@id=’foo’] | #foo |
| クラス属性がfooを含む要素 | //*[contains(@class,’foo’)] | .foo |
| title属性を含む要素 | //*[@title] | *[title] |
| pの最初の子要素 | //p/*[0] | p>*:first-child |
| 要素aを持っ全てp要素 | //p[a] | 表現不可 |
| pと同系列の次の要素 | //p/following-sibling::*[0] | p + * |
| pと同系列の前の要素 | //p/preceding-sibling::*[0] | 表現不可 |
| src属性が”.jpg”で終わるimg要素 | //img[ends-with(@src,”.jpg”)] | img[src$=”.jpg”] |
| 直下のテキストが文字列であるp要素 | //p[text()=”文字列”] | 表現不可 |
Chromeを使って、要素を特定する文字列を簡単に知る方法
Chromeのデベロッパーツールで、要素を特定できる文字列の取得が可能です。
Windowsの場合、F12でツールを開いて、Elementタブを右クリックすると、取得できます。
XPathの記述を取得
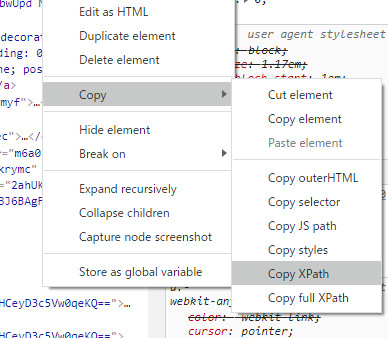
取得結果 //*[@id=”rso”]/div[4]/div/div/div[1]/a[1]/h3
CSSセレクターの記述を取得
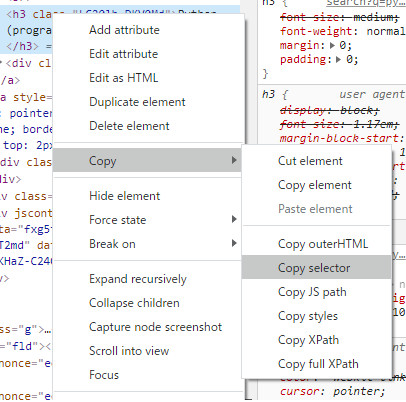
取得結果 #rso > div:nth-child(4) > div > div > div.yuRUbf > a:nth-child(1) > h3
実際にスクレイピングしていると、CSSセレクターのみ使用
CSSのみを使う理由は、2つあります。
- CSSセレクターの方が記述が簡単
- XPathが独自にもつ要素特定方法(XPathとCSSセレクターの要素特定の書き方の比較)は、使わない
XPathの「直下のテキストが文字列であるp要素」は便利で、これがあればfor文で回す必要がなく、記述も短く済み非常に便利です。ですが、それ以外の特定方法の出番はないです。
CSSセレクターでたどり難い要素は、先に親要素を見つけ、そこからfor文を回して見つけています。for文内で、正規表現を使って、より正確に探り当てます。もちろん遅いです。しかし、WEBサーバにアクセスするスクレイピングは処理スピードを求める必要はないのです。
