
openpyxlで、エクセルファイルからデータを取得するとき、エクセルの「定義された名前」で設定された名前で取得した方が都合が良いことがあります。
import openpyxl
wb = openpyxl.load_workbook('test.xlsx', read_only=True)
ws = wb['Sheet1']
ws["h3:i6"]
上の様な書き方をした場合、エクセルに行や列が追加されると、ソースコードの編集が必要になり、実に具合が良くありません。そのため、シートの保護を設定をしたくなりますが、エクセル入力者の自由を奪うことになります。
そこで、エクセルのセルの範囲に名前を付けて、その名前で値を取得するようにします。下の図では、Sheet1の”H3:I6″に”book_table_data”と名前を定義しています。
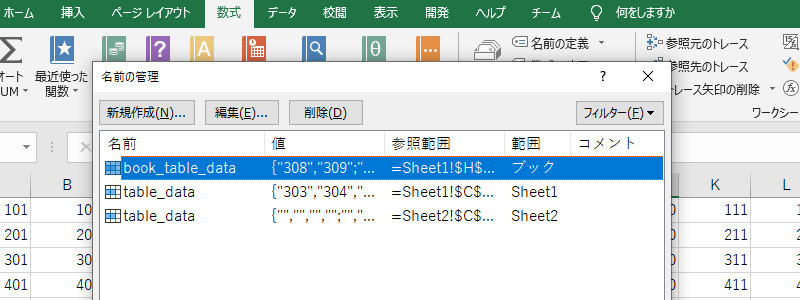
名前によるセルの値の取得方法は2種類
“book_table_data”の値の取り出し方は、下の通りです。
名前の範囲がブックの時の値の取得方法
import openpyxl
def read_table_by_book(xlsx_path: str, table_name: str) -> None:
wb = openpyxl.load_workbook(xlsx_path, read_only=True)
names = wb.defined_names[table_name].destinations # (1)
for sheet_name, range_name in names:
ws = wb[sheet_name]
rg = ws[range_name]
print(sheet_name)
for row in rg:
line = [col.value for col in row]
print(line)
read_table_by_book('test.xlsx', 'book_table_data')
Workbookのdefined_namesに、excelで付けた名前”book_table_data”を指定して、シート名とセル範囲を取得しています。その際、ジェネレータを利用しているため、複数の「シートとセル範囲」を取得できます。
ところが、(1)で取得できるシート名とセル範囲は、名前の定義の範囲に「ブック」を指定したときのみです。「シート」にした場合は、取得できません。取得しようとすると、(1)で例外が発生してしまうのです。
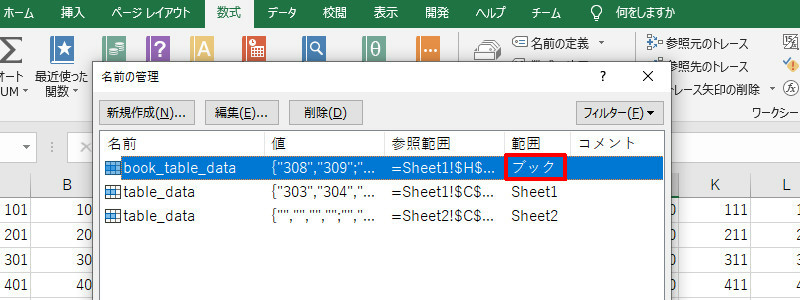
上図にある、table_dataは範囲が「シート」であるため、例外が発生します。
名前の範囲がブックかシートか確認する方法
エクセルファイルを開いて「数式タブを開いて・・・」と確認しても良いのですが、ファイルをテキストエディタで開いて見ることもできます。エクセルファイルの拡張子をzipにして展開して、workbook.xmlを探します。
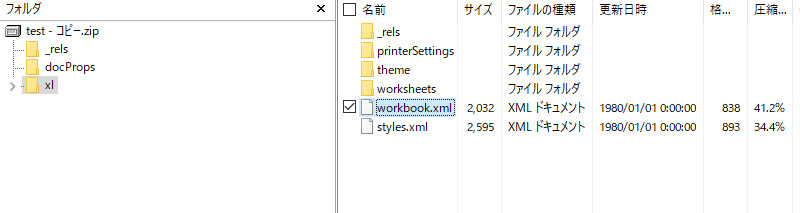
workbook.xmlをテキストエディタで開きます。

localSheetIdが設定されていると、その名前で取得しようとしたとき、(1)で例外が発生します。
名前の範囲がシートの時の値の取得方法
そこで、名前の範囲が「シート」の時は別の方法を取ります。
import openpyxl
def read_table_by_sheet(xlsx_path: str, sheet_name: str, table_name: str) -> None:
wb = openpyxl.load_workbook(xlsx_path, read_only=True)
sheet_id: int = wb.sheetnames.index(sheet_name)
attr_text: str = wb.defined_names.get(table_name, sheet_id).attr_text # (2)
print(attr_text)
ws = wb[sheet_name]
rg = ws[attr_text.split('!')[1]]
print(sheet_name)
for row in rg:
line = [col.value for col in row]
print(line)
read_table_by_sheet('test.xlsx', 'Sheet1', 'table_data')
(2)の様にWorkbookのdefined_namesで、シートIDと名前を指定すると、”Sheet1!$C$3:$F$7″とシート名とセル範囲が取得できます。後は、文字列の分割でセル範囲を分離して、値を取得できます。

